
In the previous blog post, we established that machine learning algorithms are often hard to tune, and hopefully explained the mechanism for why gradient descent has difficulty with linear combinations of losses. In this blog post, we will lay out some possible solutions.
But first, let us identify what we mean by "tunable algorithm". What is it that makes a hyper-parameter easy to tune? In order to have tunable hyper-parameters for our algorithms, we have the following desiderata:
- Preferably, the hyper-parameter has semantic meaning. This would allow finding the preferred solution in one go, without having to iterate multiple times over various parameters to narrow down the area of interest.
- By tuning the hyper-parameter, you should be able to find any solution on the Pareto front. In other words, every solution on the Pareto front should have a value for the hyper-parameter for which the optimisation algorithm finds that solution.
In order to achieve this, we reframe our optimisation problem as a Lagrangian optimisation problem instead. We choose one of the losses as the primary loss and put a constraint on the other loss. The goal is to minimise the primary loss subject to the second loss being less than a value ε. In symbols:
$$\text{Minimize}\;L_0(\theta)\;\text{subject}\;L_1(\theta)\leq\epsilon$$
In the end, the Lagrangian we end with looks the same as our original total loss linearly combined.
$$L(\theta,\lambda)=L_0(\theta)-\lambda(\epsilon-L_1(\theta))$$
However, we can be smarter about how we tackle this total loss when thinking about it as a constrained optimisation problem.
For instance, where and whether we converge on this constrained problem has been mathematically formalised in the Karush–Kuhn–Tucker (KKT) conditions. This is a bit technical and is not necessary for the rest of the post, but from those conditions, we know that the optimum we are looking for, will be a saddle point on this Lagrangian with a linear weighted combination of losses. However, we need to combine that insight with the inability of gradient descent to find saddle points to notice that there might be an issue with problems that have concave Pareto fronts.
So, we are not in the clear yet. Mixing Lagrangian optimisation with gradient descent is also a dangerous domain fraught with peril.
In this blog post, we will therefore give an overview of many approaches found in various places in literature. We will show the problems with most of these approaches, and give the approach we would suggest taking to make machine learning algorithms tunable.
Take for starters the following intuitive solve-the-dual approach, which can be found in many papers.
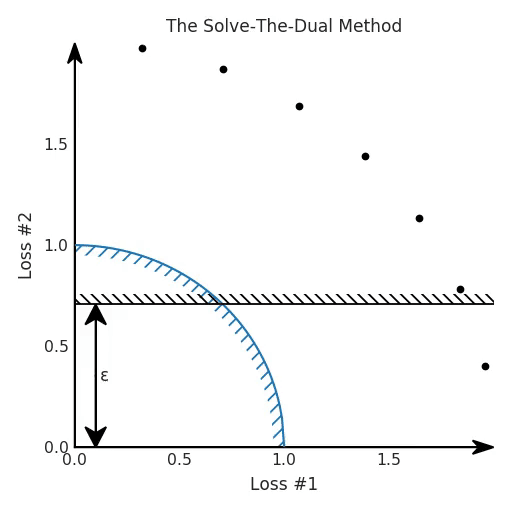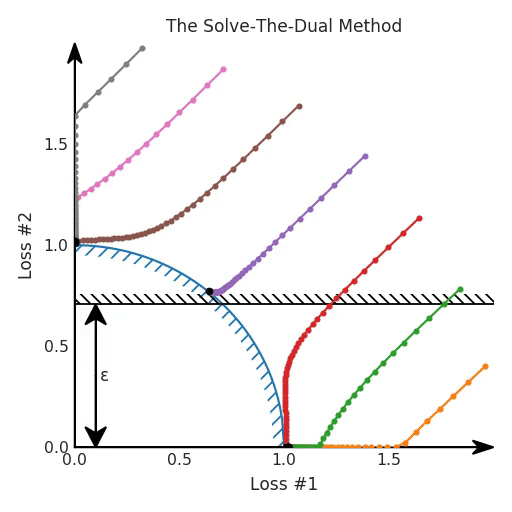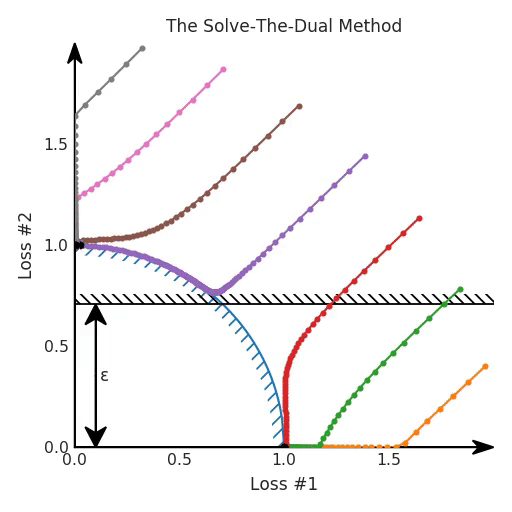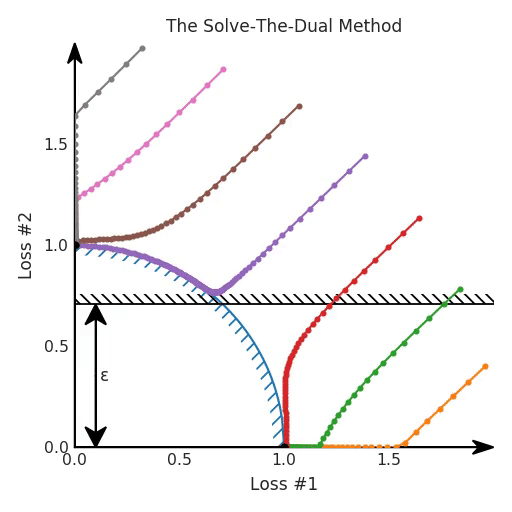
The Solve-The-Dual method
In this approach, a typical method from Lagrangian optimisation is used, and a dual is constructed and solved to find the ideal λ. We then optimise our Lagrangian with gradient descent. Intuitively, we might think that plugging in this value for λ, and optimising the Lagrangian with gradient descent will solve the constrained optimisation problem.
def loss(θ, λ, ε):
return loss_1(θ) - λ*(ε - loss_2(θ))
loss_derivative = grad(loss)
ε = 0.3
λ = solve_dual(ε) # The crux
for gradient_step in range(200):
gradient = loss_derivative(θ, λ, ε)
θ = θ - 0.02 * gradientTo visualise how this works, we have plotted the evolution of the losses for our optimisation process, colour-coded according to where the parameters were initialised. In the figure below, this constraint on loss 2 is depicted as a black hatched line, which hopefully is helpful to gain intuition on how this constrained optimisation problem relates to our original problem.

So yes, in this case, the problem is solved nicely, and it seems we could use ε in this case to tune the optimum. So we can nail the trade-off we want, without running our optimisation processes multiple times to tune this ε hyper-parameter.

However, there is an issue when we look at what happens on our reparametrised model with the concave Pareto front. It turns out that not only did we not seem to converge on the Pareto front, but some of the solutions found with gradient descent are downright ignoring our hard constraint!
The reason for this should now be clear if you read the previous blog post. Even though we solved a dual to find the optimal λ parameter that matches our ε, we are still making a linear trade-off between our losses. And as established in the previous blog post, this does not play well with gradient descent optimisation. Therefore, despite the use of this method in various papers, this approach does not work in the general case. When the Pareto front is concave, constraints can be ignored and you still cannot always find all good solutions by tuning your hyper-parameter. And in general, you do not know the shape of your Pareto front, so you do not know which case you are in.
The Hard Constraint First Method
An alternative method, which does work, is to first optimise for the constraint with gradient descent, and to optimise for the primary loss only as long as this constraint is satisfied. With this approach, the constraint will always be satisfied upon convergence, and the other loss minimised. This approach works for both the concave and the convex case.
def constraint(θ, ε):
return ε - loss_2(θ)
optimization_derivative = grad(loss_1)
constraint_derivative = grad(constraint)
ε = 0.7
for gradient_step in range(200):
while constraint(θ, ε) < 0:
# maximize until the constraint is positive again
gradient = constraint_derivative(θ, ε)
θ = θ + 0.02 * gradient
gradient = optimization_derivative(θ)
θ = θ - 0.02 * gradient
There is a major downside to this method, in that you do not really treat the trade-off between the losses during your gradient descent. Only one of the losses is being considered at every step. In general, this makes this approach less desirable for many applications.
For example, a common failure case is when your constraint has an obvious solution, which however brings it to a part of the space where the primary loss has barely any gradient to follow. Convergence can be another issue, when every time you solve the constraint, you undo the progress you have made on the primary loss.
Additionally, this method does not work that well when you want to use stochastic gradient descent rather than gradient descent. Since the constraint is defined on the average loss across all data, you do not want to enforce the hard constraint on a sample of your data where it is not satisfied yet, as long as it is satisfied in the general case. And this issue is hard to overcome.
However, this method is easy to implement and might actually work sufficiently for your particular problem.
Basic Differential Multiplier Method
So, from the previous section, we know that solutions do exist that can handle this constrained optimisation problem using gradient descent. If we return to the idea of using a Lagrangian to solve the constrained version of our problem, we can see that the fundamental issue is the interaction between a fixed λ found by solving the dual function and using gradient descent to minimise the other parameters. Could we not use a single gradient descent to find both the optimal parameters and Lagrangian multiplier simultaneously?
Yes, that is in fact possible. Take the following algorithm:
def lagrangian(θ, λ, ε):
return loss_1(θ) - λ*(ε - loss_2(θ))
derivative = grad(lagrangian, (0,1))
ε = 0.7
λ = 0.0
for gradient_step in range(200):
gradient_θ, gradient_λ = derivative(θ,λ,ε)
θ = θ - 0.02 * gradient_θ # Gradient descent
λ = λ + 1.0 * gradient_λ # Gradient ascent!
if λ < 0:
λ = 0
We follow the gradient of the Lagrangian downwards for the parameters, but upwards for λ. So gradient descent for the parameters, but gradient ascent for the Lagrangian multipliers. As long as we take care that λ is not becoming negative, since we formulated our constraint as an inequality, we should be golden. Note that we really want λ to become exactly zero when the constraint is satisfied! Parametrising it as a softplus or even an exponential to keep it positive, is a bad idea, even though you might find it in a number of publications.

This approach does work nicely on the convex case. It has the upside that at every gradient step, both of the losses are considered. This makes this approach applicable to stochastic gradient descent as well, at the cost of a little additional intricacy of understanding how Lagrangians work. Also, note that it is still possible to use a single gradient evaluation for both the gradient descent and the gradient ascent. Therefore, the computational complexity broadly stays the same.
However, it does not solve our original problem in the general case, and that becomes clear when we take a look at how this algorithm behaves on the concave Pareto front case.

While the performance is fair, it does not converge to a solution. This optimisation method keeps oscillating on the Pareto front, unable to settle on a good solution. Therefore, this method can give the appearance of finding better solutions, but it still is not tunable. The method can however be found in various papers, because if one cherry-picks when to stop the optimisation process, one can probably find the solution which would be most suitable to convince the peer reviewers. Yet, it is disappointingly hard to use this method when manual intervention is not possible. For example, when the optimisation process is just a piece in a larger puzzle, as is the case in for instance reinforcement learning.
Modified Differential Method of Multipliers
Finally, this section will introduce a solution here, which as far as we can tell was introduced to the field of machine learning for the first time in a NIPS paper in 1988 by John C. Platt and Alan H. Barr.
The method is easier to understand after we identify on an intuitive level what is causing the oscillations in the previous figure. This can be found if we follow the behaviour of the parameters as it oscillates around the optimum. As long as the constraint is violated, λ keeps increasing. But when we are suddenly satisfying the constraint again, λ is still large. It will take a number of steps before the gradient descent will push λ back to zero. As long as λ is positive, the solution is pushed further away from the constraint. Eventually, λ becomes zero, the constraint is ignored and the optimisation process continues. However, when the solution accidentally hits the constraint again, the whole cycle repeats. Intuitively, you can think of the Lagrangian multiplier λ as the potential energy of an oscillating system.
From that perspective, the authors of the NIPS paper introduce damping on this energy in their Modified Differential Method of Multipliers. With this damping, you can prevent the system from oscillating eternally, and make it converge instead.
The paper has become harder to read as machine learning has settled on different conventions for thinking about optimisation problems, so we will not discuss the notation used in the paper. However, we can reformulate their ideas from over 30 years ago into a more contemporary Jax code in the following way.
damping = 10.0
def lagrangian(θ, λ, ε):
damp = damping * stop_gradient(ε-loss_2(θ))
return loss_1(θ) - (λ-damp) * (ε-loss_2(θ))
derivative = grad(lagrangian, (0,1))
ε = 0.7
λ = 0.0
for gradient_step in range(200):
gradient_θ, gradient_λ = derivative(θ, λ, ε)
θ = θ - 0.02 * gradient_θ
λ = λ + 1.0 * gradient_λ
if λ < 0:
λ = 0Indeed, this method does work nicely for both convex and concave Pareto fronts, as illustrated in the following figures.
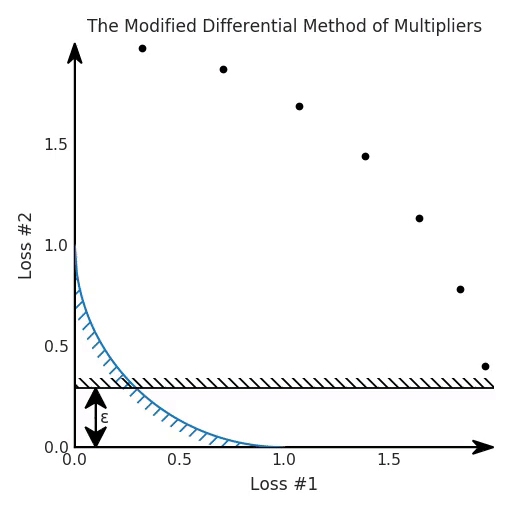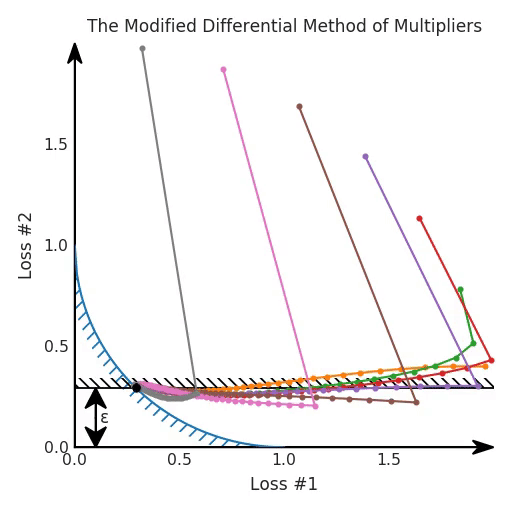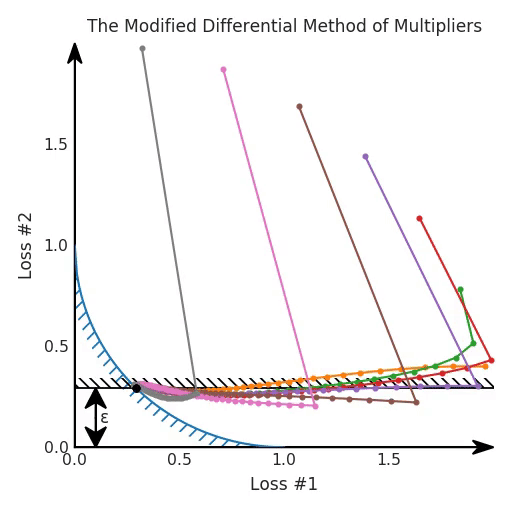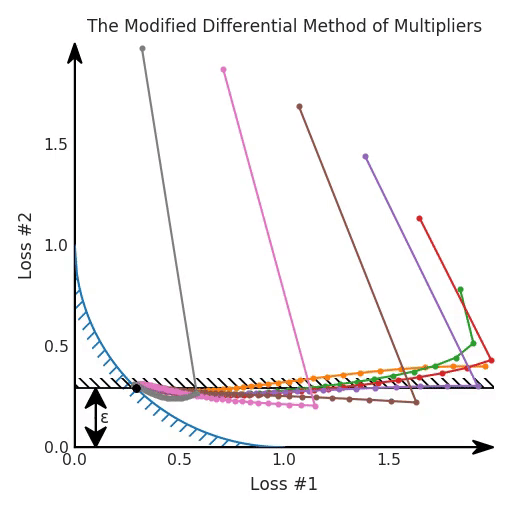

It does come with a slight downside, namely that you now have a damping hyper-parameter. This additional parameter trades the time to find the Pareto front with the time to converge to a solution on that front. Note that the damping parameter does not alter which solution is found, only how fast it is found.
However, that perspective of “oh no, not an additional hyperparameter” is only muddying the waters. It is the first time in this article that we have a tunable algorithm that works for stochastic gradient descent! We can use this Modified Differential Method of Multipliers to tune the balance between the losses in a semantically useful way using stochastic gradient descent, no matter the shape of the invisible Pareto front.
In our limited experience, this is the method which should be used more often. In fact, we would postulate that wherever you see a linear combination of losses being optimised with gradient descent, this more principled approach could be used.
In those cases where currently a linear combination of losses is used, the constrained reformulation of that problem is going to yield more general and tunable algorithm.
Conclusion
In this blog post, we hopefully illustrated an approach to trade poorly tunable algorithms caused by linearly combined losses for more robust approaches with semantically relevant hyper-parameters. Note that while this does come with some more headroom to understand the optimisation process, it does not cause additional computational complexity. In fact, in the Jax examples used here, it was implemented with only 6 additional lines of code.
The upside of this approach is that significantly less effort will be spent on tuning hyper-parameters. Optimisation procedures don't need to be iterated on as much, and they will be more robust to where the parameters were initialised as well.
If you like this blog post, it would mean the world to us if you could leave a comment below. Let us know what you think, e.g. whether you learned something or if we were stating the obvious, and if we should write more blog posts like this.
